1 Preface
What is Spring Cloud Data Flow, although it has been around for a while, I think many people don’t know about it, because few people use it in their projects. Not much information can be found online.
Spring Cloud Data Flow is a microservices-based, specialized framework for streaming and batch data processing.
2 Basic concepts
2.1 Data Processing Modes
There are two modes of data processing, Streaming and Batch processing. Streaming is long time always, I process when your data comes, I wait when it doesn’t, based on message driven. Batch is a shorter processing time, start once and process once, then exit the task, need to go to trigger the task.
Generally, we develop Streaming applications based on the Spring Cloud Stream framework and Batch applications based on the Spring Cloud Task or Spring Batch framework. Once the development is done, it can be packaged into two forms.
Springboot-stylejarpackages that can be placed onmavenrepositories, file directories, orHTTPservices.Dockerimages.
For Stream, there are three concepts that need to be understood.
Source: the message producer, responsible for sending messages to a certain target.Sink: a message consumer, responsible for reading messages from some target.Processor: the union ofSourceandSink, which consumes messages from a target and sends them to another target.
2.2 Features
Spring Cloud Data Flow has many good features to learn how to use it.
- A cloud-based architecture that can be deployed on
Cloud Foundry,KubernetesorOpenShift, etc. - A number of optional out-of-the-box stream processing and batch application components.
- Customizable application components based on a
Springbootstyle programming model. - Simple and flexible
DSL (Domain Specific Language)to define task processing logic. - Beautiful
Dashboardto visually define processing logic, manage applications, manage tasks, etc. - Provides
REST APIto interact inshellcommand line mode.
2.3 Server-side components
The server side has two important components: Data Flow Server and Skipper Server. The two have different roles and collaborate with each other.
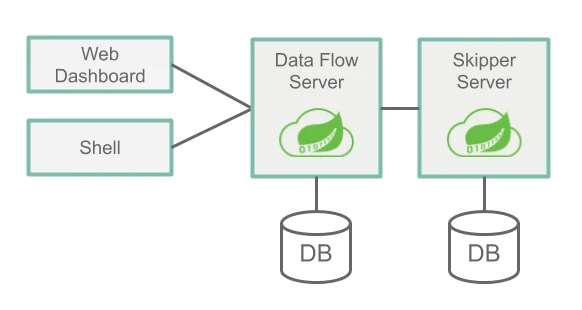
The main roles of the Data Flow Server are
- Parsing the
DSL. - Verifying and persisting the definitions of
Stream,TaskandBatch. - Registering applications such as
jarpackage applications anddockerapplications. - Deploying
Batchto one or more platforms. - Querying the execution history of
JobsandBatches. - Configuration management of
Stream. - Distribution of
Streamdeployments toSkipper.
The main roles of the Skipper Server are.
- Deploying
Streamto one or more platforms. - Updating or rolling back
Streamsbased on a grayed-out/greened-out update policy. - Save the description information of each
Stream.
As you can see, if you don’t need to use Stream, you can deploy Skipper without it. Both rely on a relational database (RDBMS) and by default use the built-in H2, supported by H2, HSQLDB, MYSQL, Oracle, PostgreSql, DB2 and SqlServer.
2.4 Runtime environment
The good Spring is always particularly decoupled, and the Server and application can run on different platforms. We can deploy Data Flow Server and Skipper Server on Local, Cloud Foundry and Kuernetes, and Server can deploy the application on different platforms.
- Server-side Local: application Local/Cloud Foundry/Kuernetes.
- Server-side Cloud Foundry: applying Cloud Foundry/Kuernetes.
- Server-side Kuernetes: Apply Cloud Foundry/Kuernetes.
In general, we deploy Server and application on the same platform. For production environments, it is recommended that it is more appropriate to be on Kuernetes.
3 Local mode installation and use
For a quick experience, we use the simplest local runtime environment.
3.1 Downloading Jar Packages
Download the following three jar packages.
|
|
For a simple Batch application, you can just download spring-cloud-dataflow-server-2.5.3.RELEASE.jar.
3.2 Starting the application
After the launch is complete, open your browser and visit http://localhost:9393/dashboard to see the UI interface.
3.3 Deploying applications
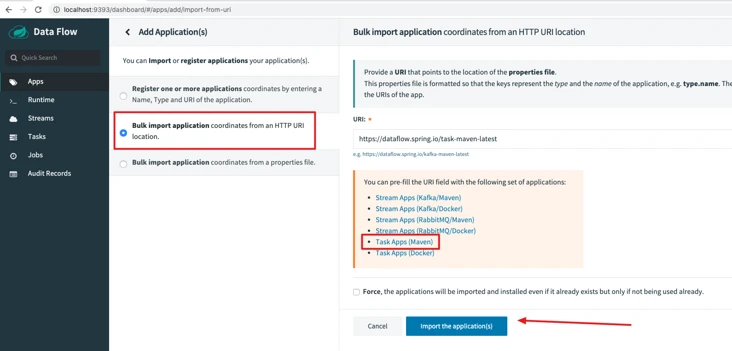
3.3.1 Adding ApplicationsApplications
You can only deploy Batch and Stream if you have added applications. The official example Applications is provided and we can use it directly.
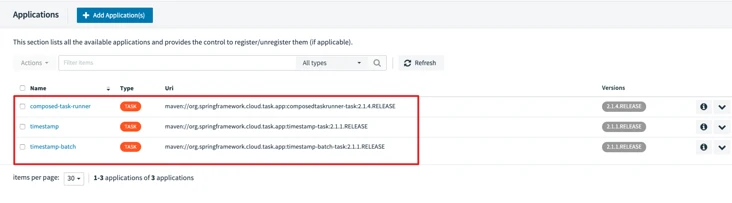
After successful addition, you can view in the application list.
3.3.2 Creating a Task
Creating a Task can be done graphically or through the DSL, which is very convenient.
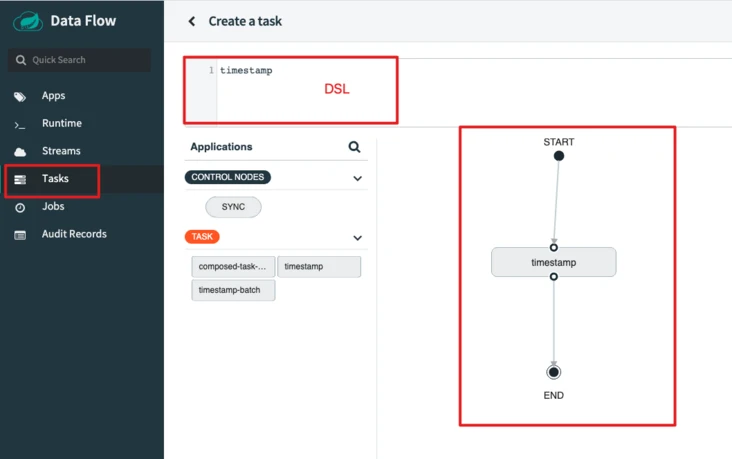
After defining the Task, enter the name to create.
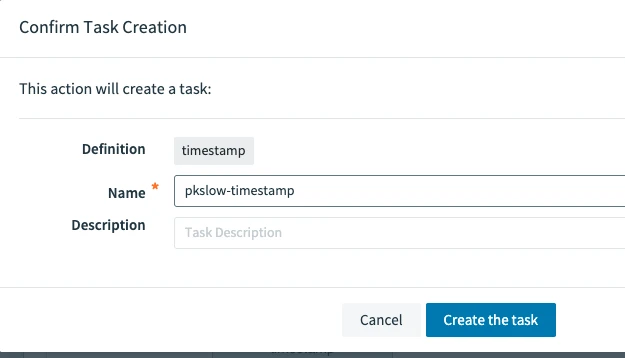
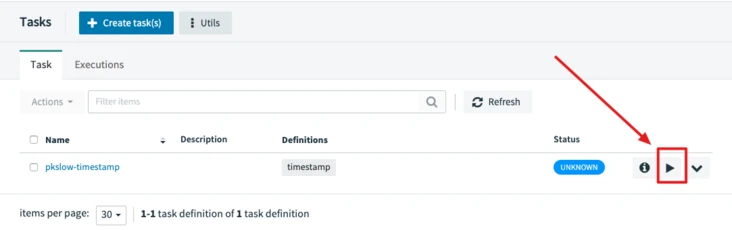
3.3.3 Running a Task
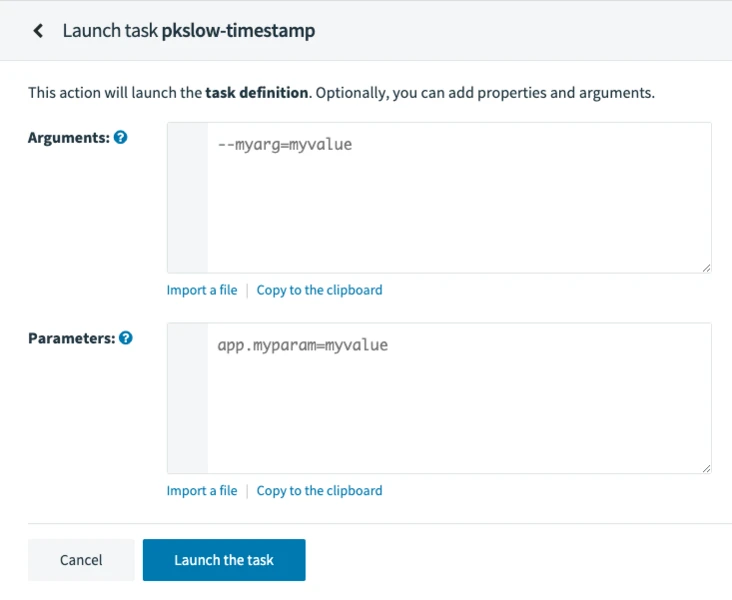
Run directly by clicking on.
Parameters can be passed in.
3.3.4 Viewing Task Runs
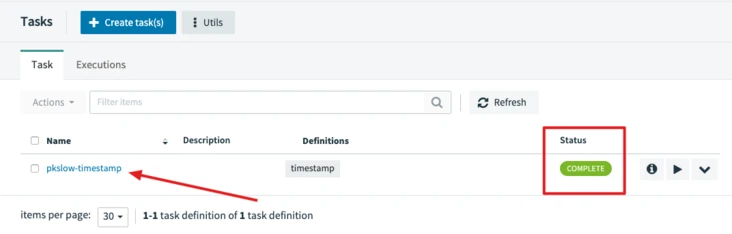
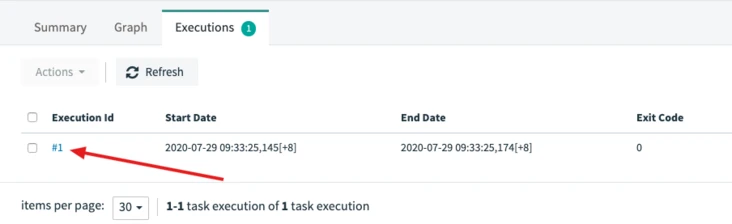
You can view the run log.
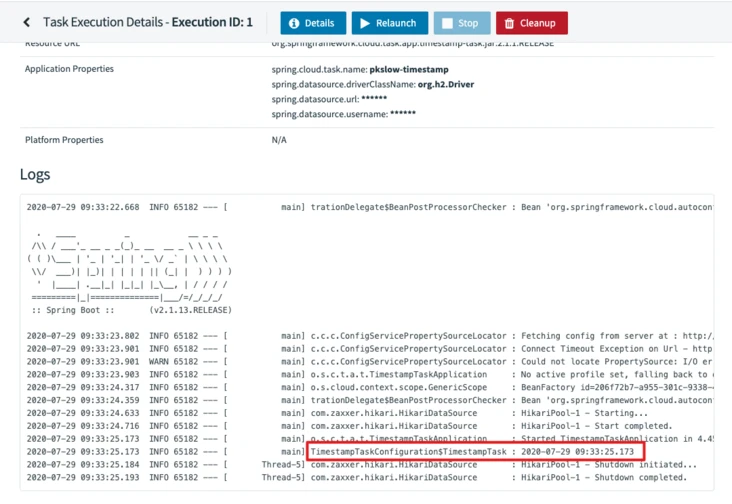
3.4 Data Flow Shell Command Line(CLI)
In addition to the web page, you can also interact with Server via command line mode.
To start the application.
|
|
4 Summary
This article uses the official application, we can develop our own application and register it on Server. The Local model is suitable for development environments, but production environments are more reliable when deployed on Kubernetes. Let’s explore it later.