Today, there are still many people arguing about cyclic dependencies, and many interviewers asking questions about cyclic dependencies, and even asking only about cyclic dependencies in Spring, which seems to be a must learn point in Spring, a feature that many people are talking about. In my opinion, this is a bit of a stain on the many good designs in the Spring framework, a compromise for bad design, you know, there are no circular dependencies in the whole Spring project, is this because the Spring project is too simple? Quite the contrary, Spring is much more complex than most projects. Similarly, in Spring-Boot 2.6.0 Realease Note it is stated that cyclic dependencies are no longer supported by default, and if you want to support them you need to enable them manually (they were enabled by default before), but it is highly recommended to break cyclic dependencies by modifying the project.
In this post I would like to share my thoughts about cyclic dependencies, but of course, before I do that, I will take you through some knowledge about cyclic dependencies.
Dependency Injection
Since circular dependencies occur during dependency injection, let’s briefly review the process of dependency injection.
Case in point.
The above is a very simple Spring starter case where Foo is injected into Bar , which happens in context.getBean("foo").
The process is as follows.
- through the incoming “foo”, find the corresponding
BeanDefinition, if you do not know what isBeanDefinition, then you can understand it as an object that encapsulates the corresponding Class information of the bean, through which Spring can get the beanClass and some annotations of the beanClass logo. - use the beanClass in
BeanDefinition, instantiate it by reflection, and get what we call a bean (foo). - Parse the beanClass information and get the property (bar) that identifies the
Autowiredannotation. - using the property name (bar), call
context.getBean('bar')again, and repeat the above steps - Set the value of the obtained bean(bar) to the property(bar) of foo
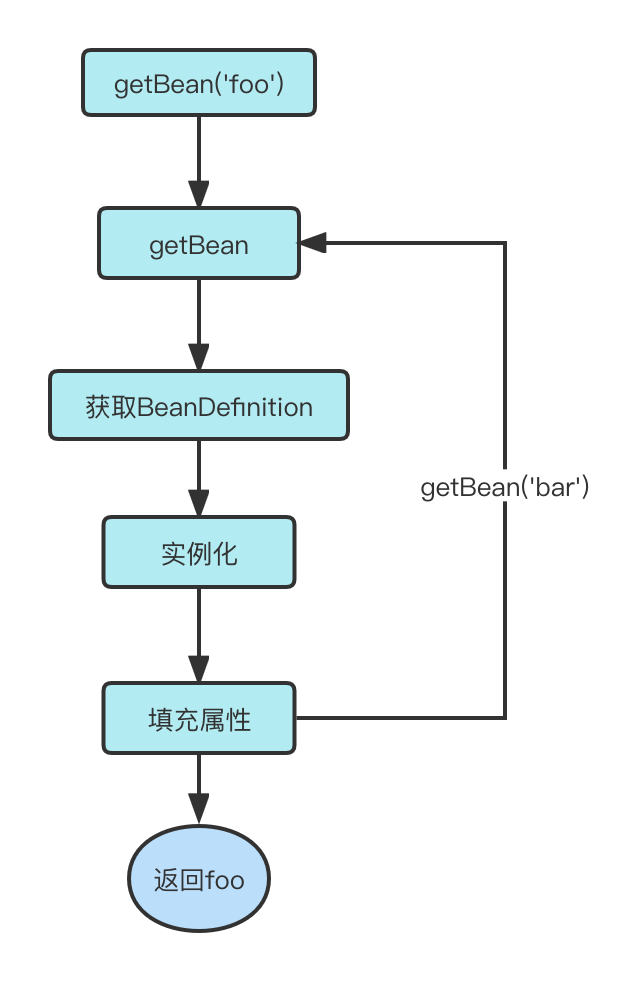
The above is a brief description of the process.
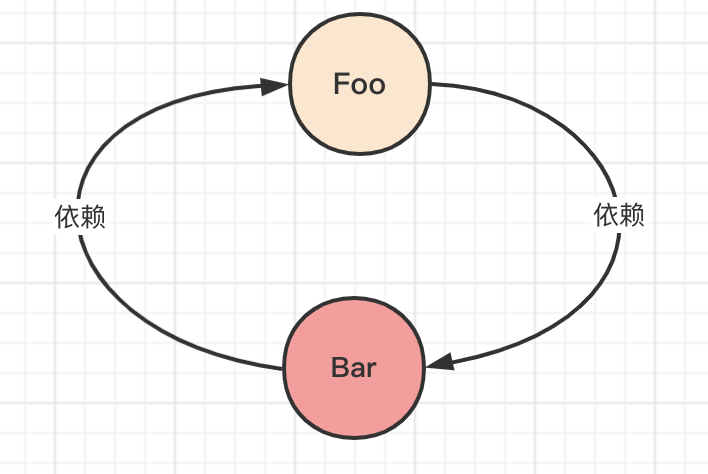
What is a circular dependency
A circular dependency is when A depends on B and B also depends on A, thus forming a loop.
How Spring solves circular dependencies
The process of getBean can be said to be a recursive function, and since it is a recursive function, there must be a recursive termination condition, and in getBean, it is obvious that this termination condition is returned in the process of filling the properties. So what happens if the existing process is Foo dependent on Bar and Bar dependent on Foo?
- Create a Foo object
- Find out that the Foo object depends on the Bar when filling properties
- Create a Bar object
- Fill the property when found that the Bar object depends on Foo
- Create a Foo object
- Find the Foo object depends on Bar when filling properties ….
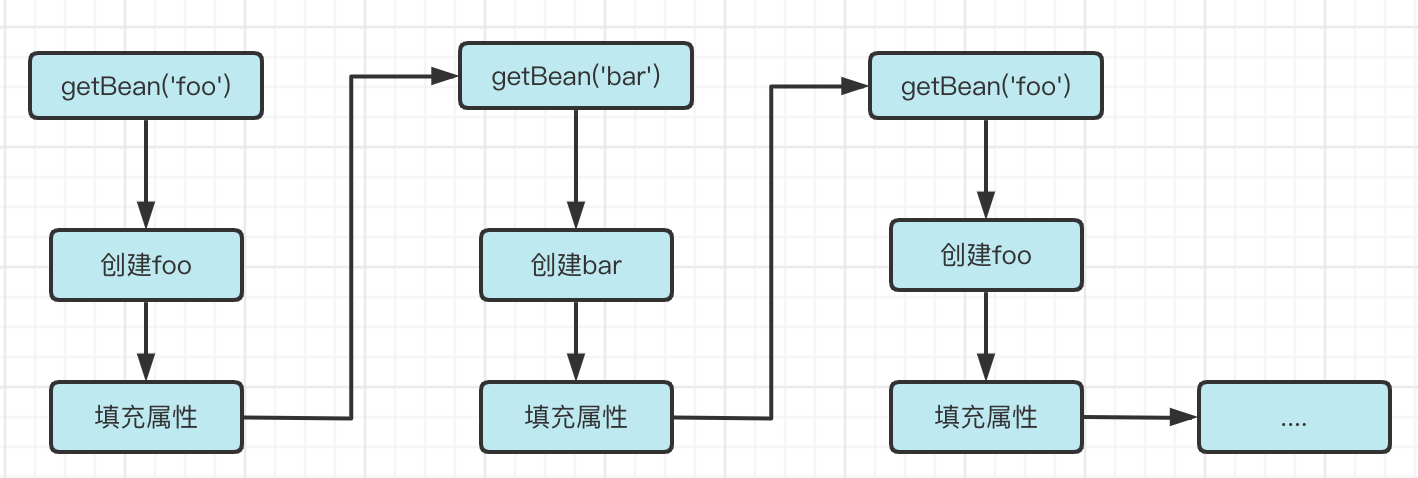
Obviously, recursion becomes a dead loop at this point, how to solve such a problem?
Adding a cache
We can add a layer of cache to the process, put the object into the cache after instantiating the foo object, and fetch it from the cache every time we get the bean, and then create the object if we can’t.
The cache is a Map, key is beanName, value is Bean, after adding the cache, the process is as follows.
- getBean(‘foo’)
- get foo from the cache, not found, create foo
- Create, put foo into the cache
- fill the properties found when the Foo object depends on Bar
- getBean(‘bar’)
- get bar from cache, not found, create bar
- Create, put bar into cache
- Find the Bar object depends on Foo when filling properties
- getBean(‘foo’)
- get foo from cache, get foo, return
- set the value of foo to the bar property, return the bar object
- set the bar to the foo property, return
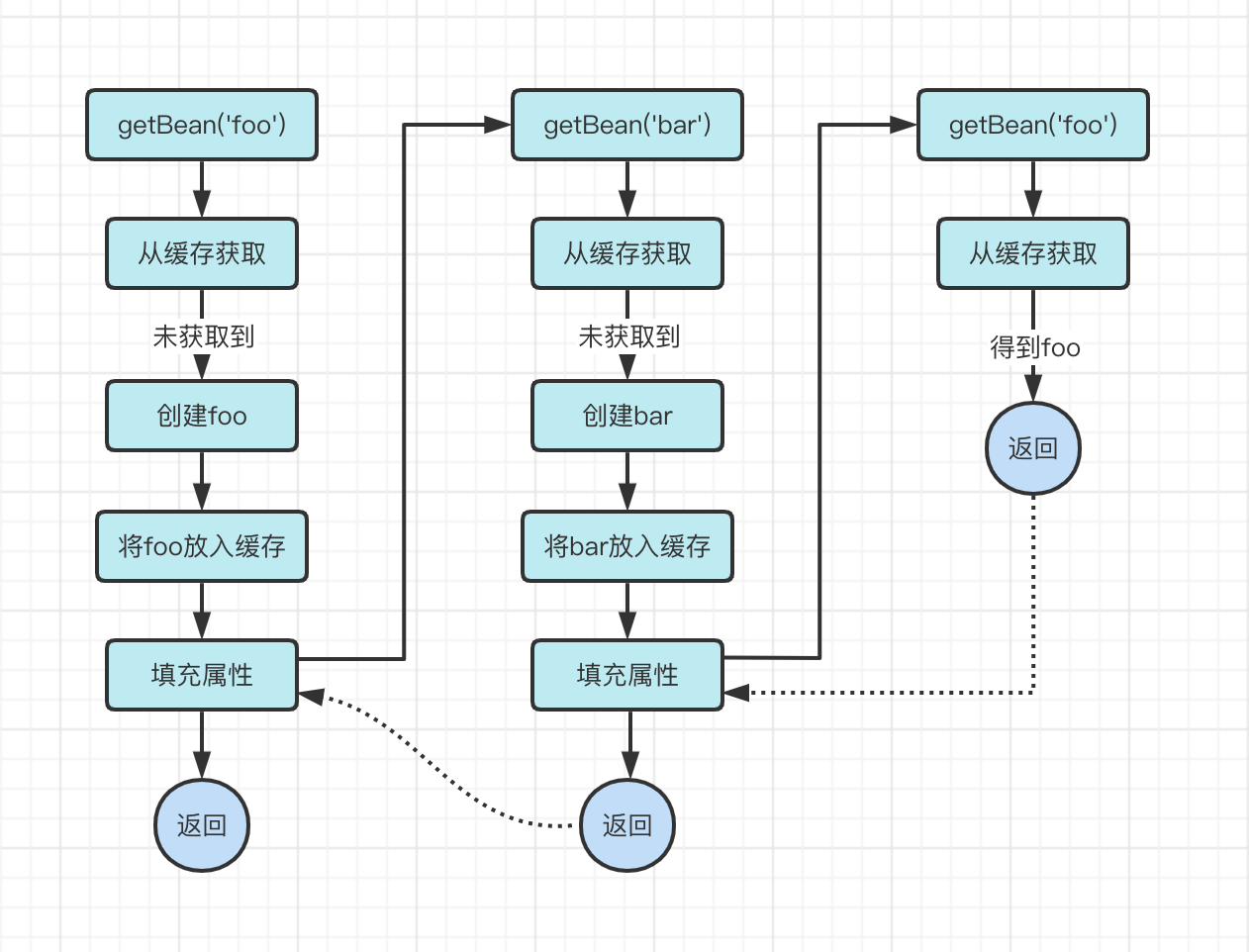
After adding a layer of caching to the above process we found that it does solve the problem of circular dependencies.
Null pointer problem in multi-threaded cases
As you may have noticed, this design is problematic when there is a multi-threaded situation.
Let’s assume there are two threads that are gettingBean(‘foo’)
- Thread one is running code that fills the property, which is just after putting foo into the cache
- Thread 2 is a little slower and is running code that gets foo from the cache
At this point, let’s say thread one hangs and thread two is running, then it will perform the logic of getting foo from the cache, at which point you will find that thread two gets foo because thread one just put foo into the cache and at this point foo hasn’t been populated with properties!
If thread two gets the foo object that has not been set to a value (bar) and happens to use the bar property inside the foo object, then it will get a null pointer exception, which is not allowed!
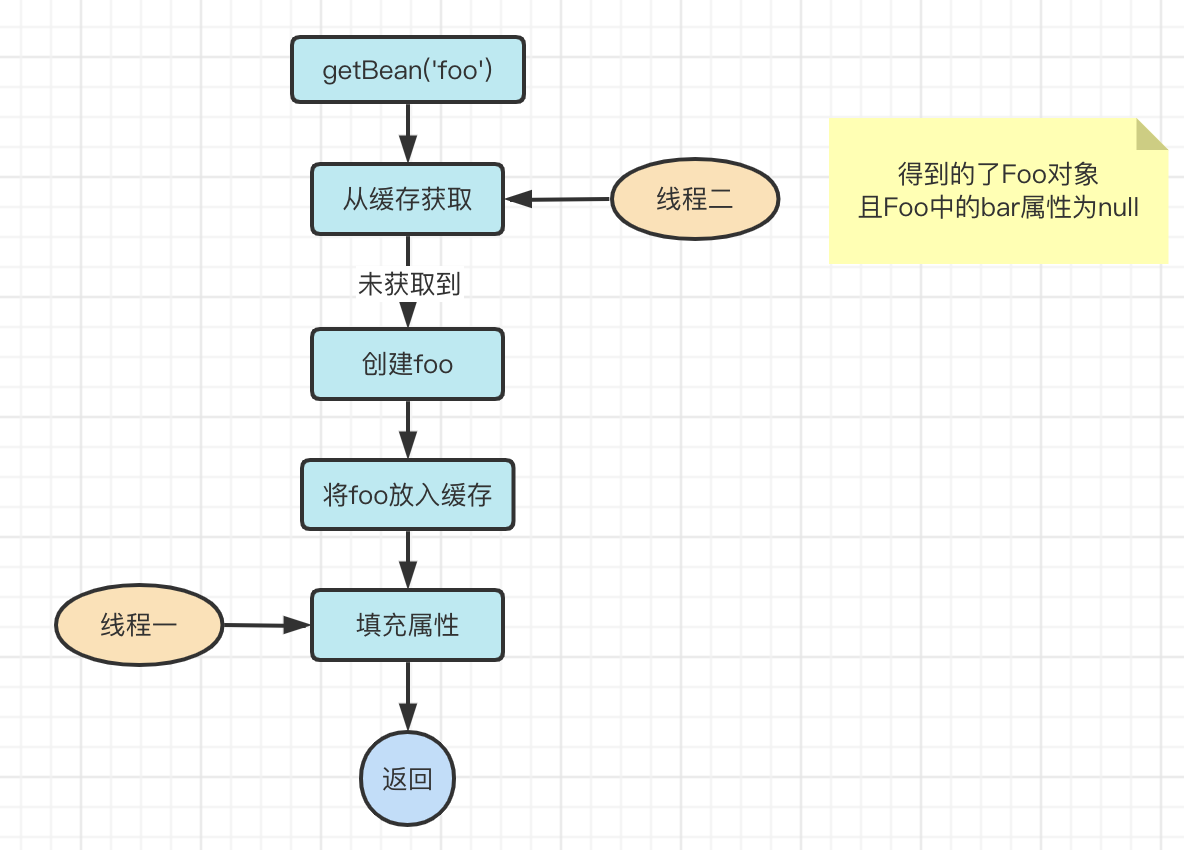
So how do we solve this new problem?
Locking
The easiest way to solve the multi-threaded problem is to use locks.
We can lock before [fetching from cache] and unlock after [filling properties].
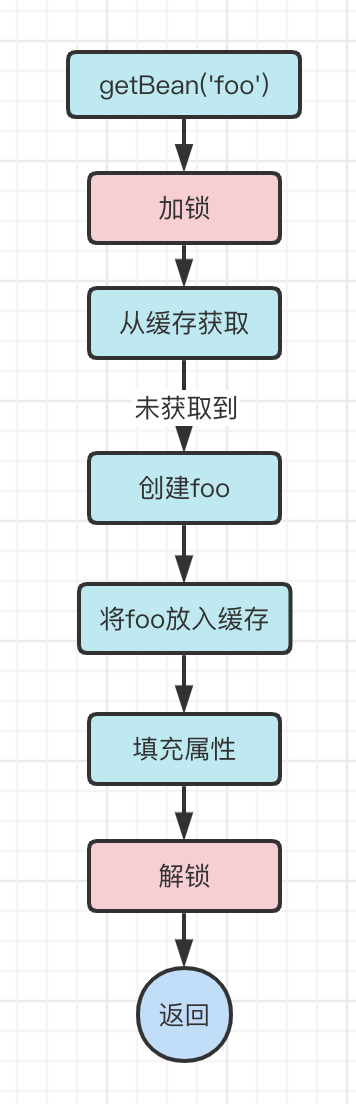
In this case, thread two must wait for thread one to complete the entire getBean process before fetching the foo object in the cache.
We know that locking can solve the multi-threaded problem, but we also know that locking can cause performance problems.
Imagine that locking is to ensure that the object in the cache is a complete object, but what if all the objects in the cache are complete? Or what if some of the objects are already complete?
Suppose we have three objects A, B and C
- A object has been created, the cache of A objects is complete
- B object is still being created, the cache of the B object some properties have not been filled
- C object has not been created
At this point we want to getBean(‘A’), so what should we expect? Do we expect to get the A object directly from the cache and return it? Or should we wait for the lock to be fetched before getting the A object?
Obviously we expect to get the A object back directly, because we know that the A object is complete and we don’t need to get a lock.
But it is also clear that the above design does not meet that requirement.
Second-level cache
The above question can actually be simplified to how to distinguish a complete object from an incomplete object? Because as long as we know that this is a complete object, then we return it directly, and if it is an incomplete object, then we need to get a lock.
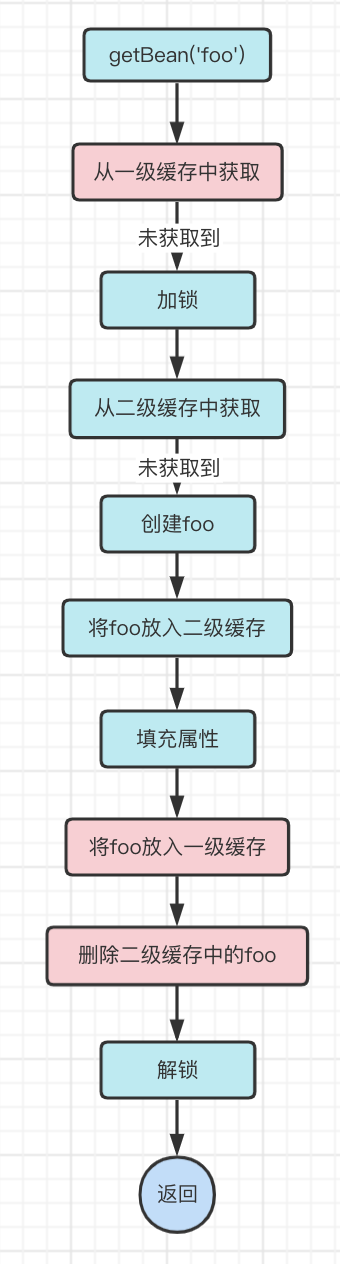
We can do this, and then add a level of cache, the first level of cache to store the complete object, the second level of cache to store the incomplete object, because such objects are put into the cache when the bean is just created, so we call it early object here.
At this point, when we need to get A object, we only need to determine whether there is A object in the first level cache, if there is, it means that A object is complete and can be directly returned to use, if not, it means that A object may not have been created or is being created, continue the logic of adding lock -> get object from the second level cache -> create object.
At this point the flow is as follows.
- getBean(‘foo’)
- get foo from the first level of cache, did not get
- Locking
- get foo from the second level cache, did not get
- Create foo object
- Put the foo object into the second level cache
- Fill properties
- the foo object into the first level of cache, the foo object is now a complete object
- delete the foo object in the second-level cache
- Unlock and return
Based on the existing process, let’s simulate the situation when the cyclic dependency appears.
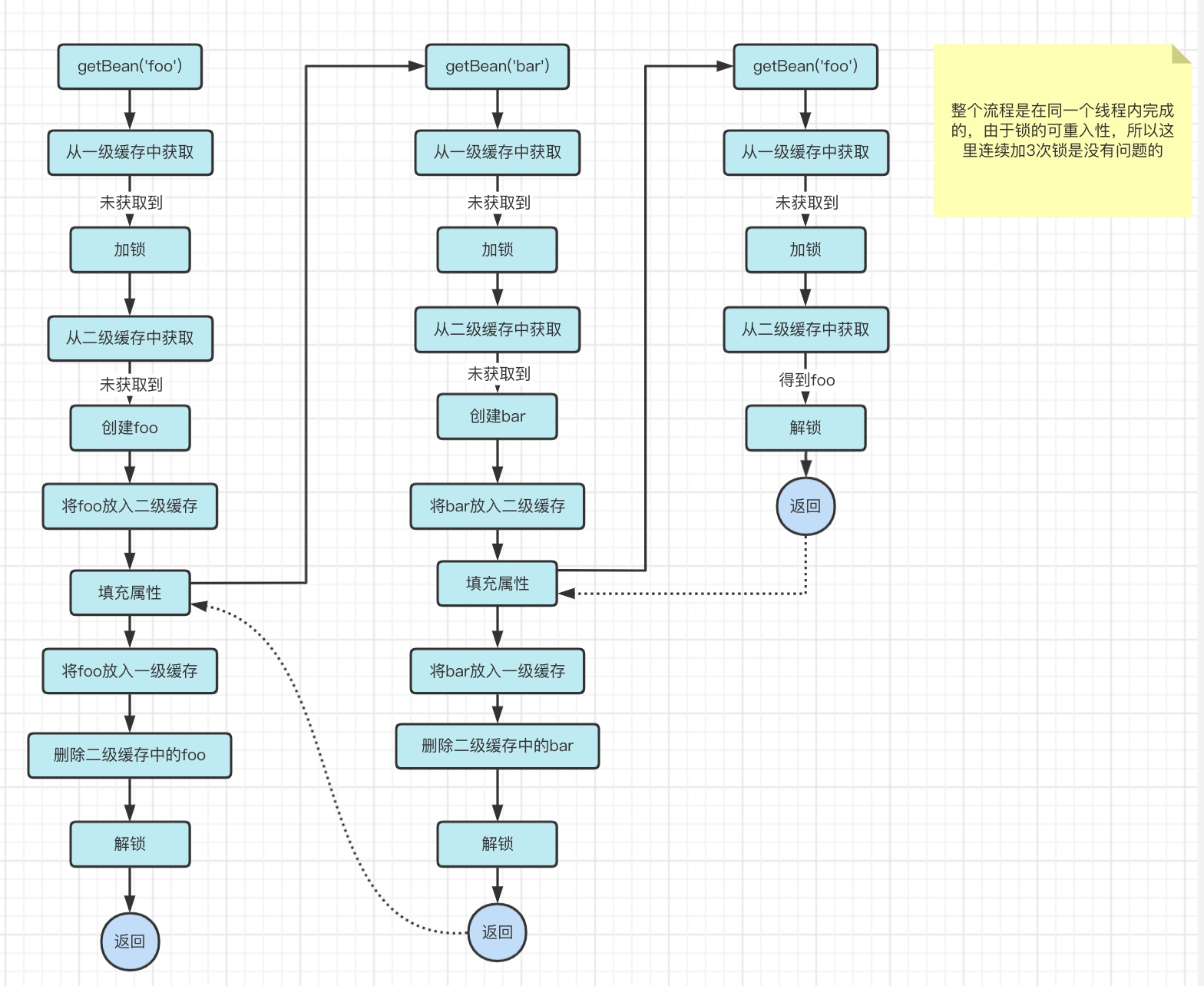
Now, it solves the object completeness problem and meets our performance requirements at the same time. perfect!
Proxy objects
Knowing that there are not only normal objects in Java, but also proxy objects, is it possible to meet the requirements when creating proxy objects that have circular dependencies?
Let’s first understand when a proxy object is created.
In Spring, the logic of creating proxy objects is at the last step, which is often called [after initialization].
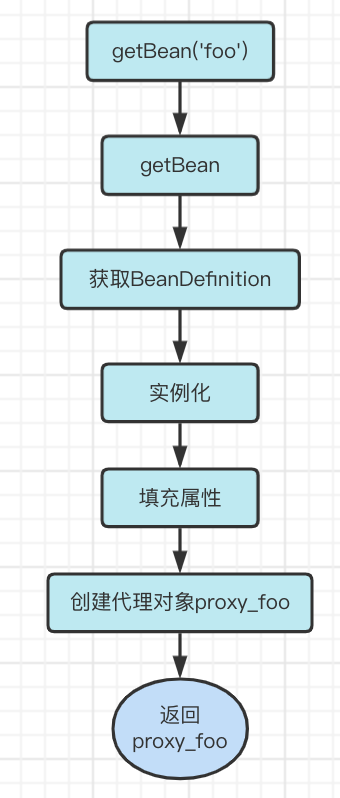
Now, let’s try to add this part of logic to the previous process.
Obviously, the last foo object is actually a proxy object, but the bar dependency is still a normal foo object!
So, when there is a circular dependency on the proxy object, the previous process does not satisfy the requirement!
So how should this problem be solved?
Thinking
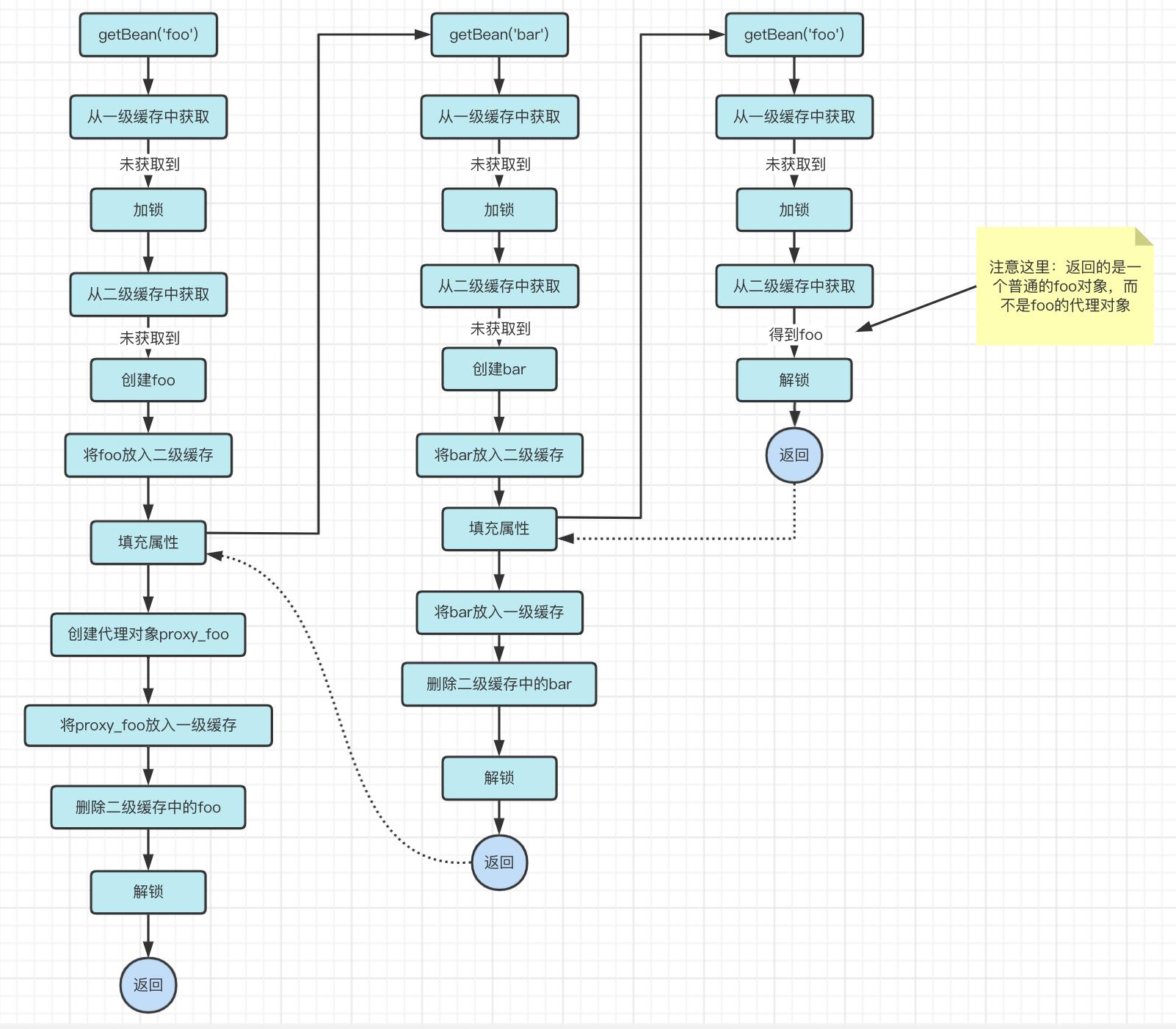
The reason for the problem is that when the bar object goes to get the foo object, the foo object from the secondary cache is a normal object.
So is there any way to add some judgment here, for example, to determine whether the foo object is to be proxied, and if so to create a proxy object for foo, and then return the proxy object proxy_foo.
Let’s assume this solution is feasible and then see if there are any other problems.
According to the flowchart we can find a problem: the proxy_foo is created twice!
- In the process of
getBean('foo'), the proxy_foo is created once after the property is filled - When the
getBean('bar')process fills the property, it also creates a proxy_foo when it gets foo from the cache
And these two proxy_foo is not the same! Although the foo object referenced in proxy_foo is the same, this is unacceptable.
How to solve this problem?
Three-level cache
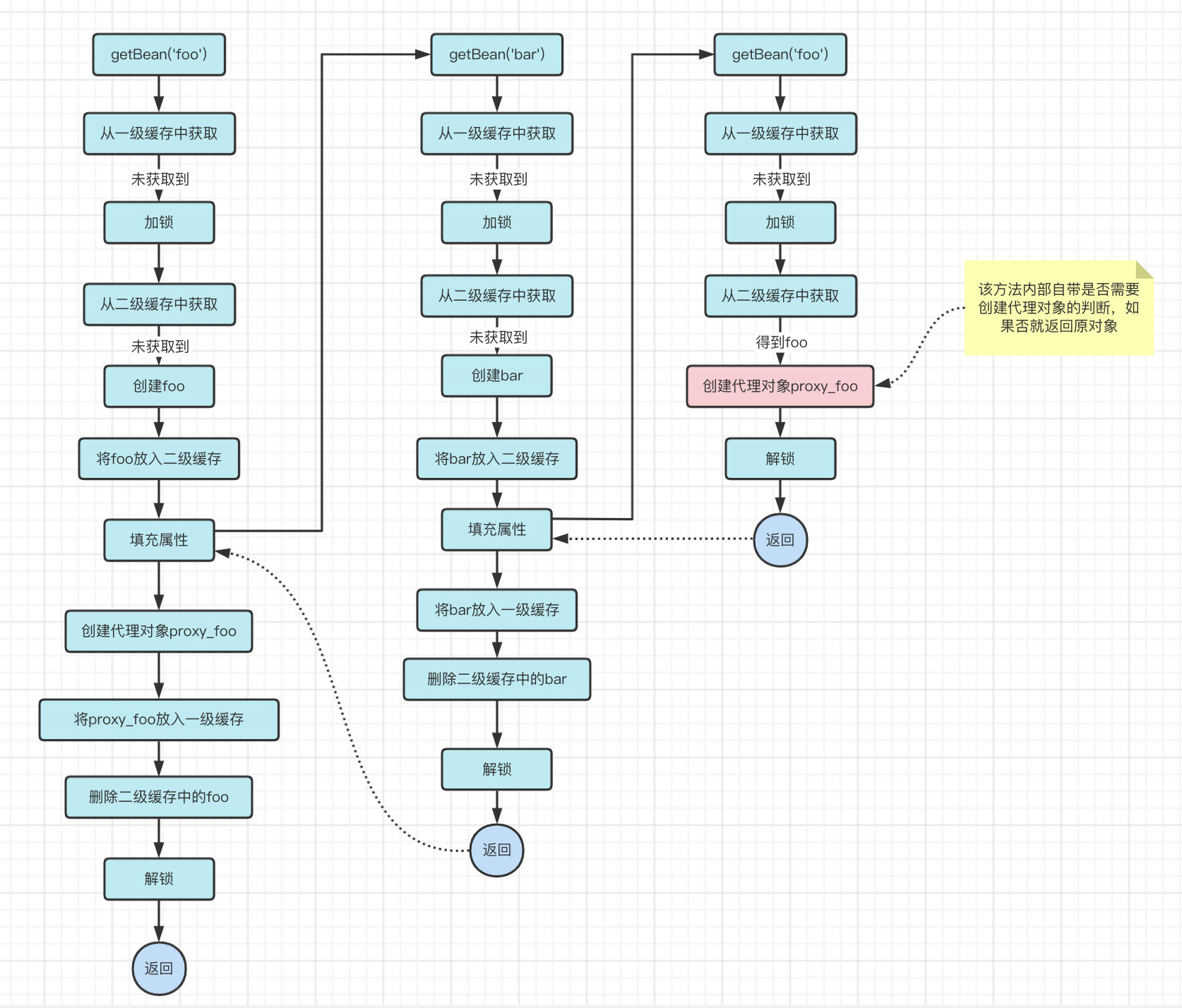
We know that the proxy_foo created twice is not the same, so how should the program know about it? That is, if we can add a marker to identify that the foo object has already been proxied, so that the program can use this proxy directly and not create another proxy. Wouldn’t that solve the problem?
The flag is not something like flag=ture or false, because even if the program knows that foo has been proxied, the program still has to get the proxy_foo, that is, we still have to find a place to store the proxy_foo.
This time we need to add another level of cache.
The logic is as follows.
- when the foo from the cache, and foo is proxied, then the proxy_foo into this level of cache.
- in the
getBean('foo')process, when creating a proxy object, first check whether there is a proxy object in the cache, and if so, use the proxy object
Here you may have a question: Shouldn’t we first determine whether there is a proxy_foo in the three-level cache, and then create a proxy_foo if there is not? Why do you create it regardless of whether there is one or not?
Yes, here the proxy_foo is created anyway. it just determines if there is an object in the tertiary cache at the end, and if so, the object in the tertiary cache is used, and the previously created proxy_foo is not used.
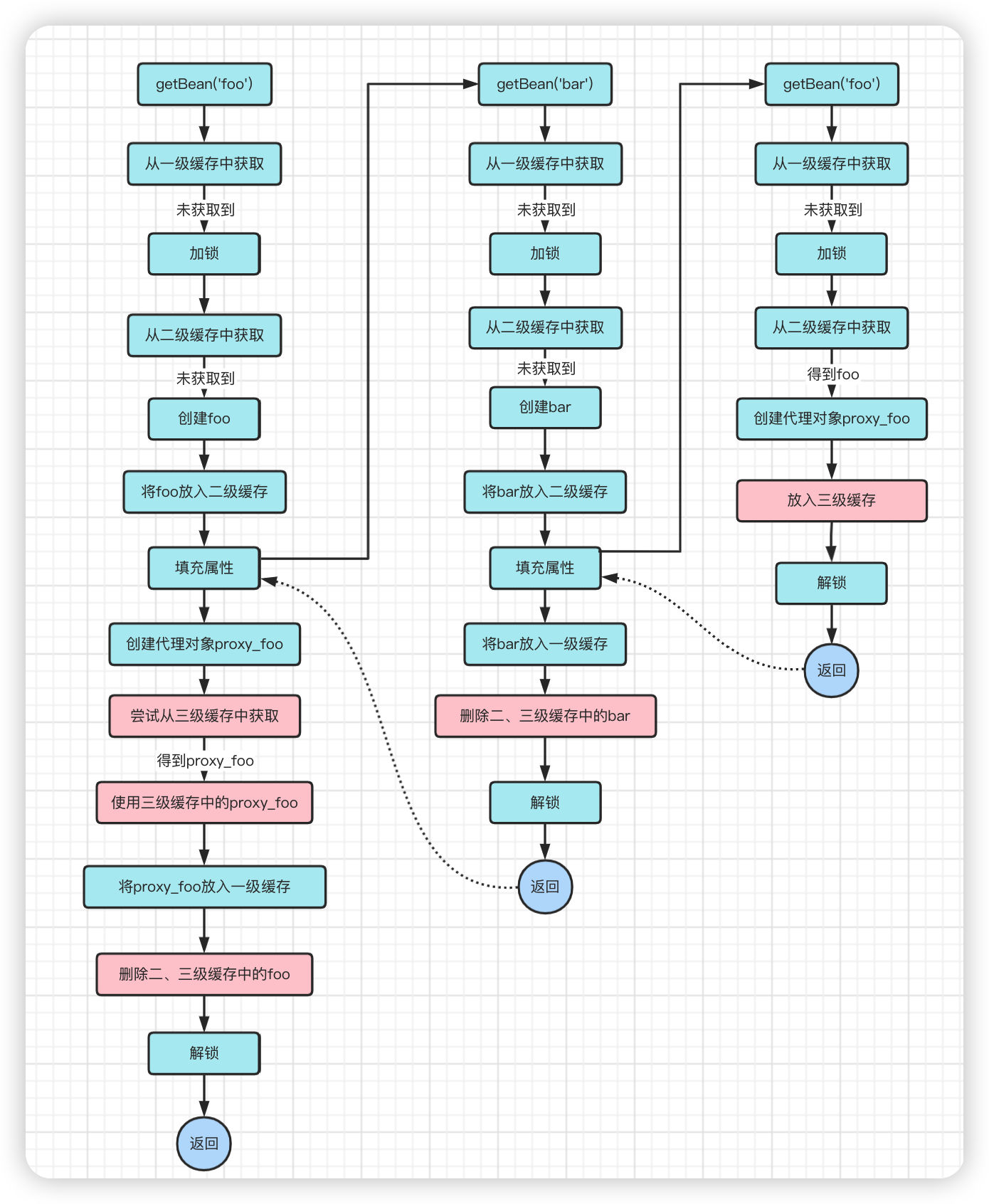
The reason is this, we know that the logic of creating a proxy object is done in a post-processor in the process of Bean [after initialization], and the post-processor can be customized by the user, so the reverse means that Spring has no control over this part of the logic.
We can assume that we have implemented a post-processor ourselves, and instead of creating a proxy object proxy_foo, this processor replaces foo with dog, and if you go with the previous idea (just determine if it is a proxy object) you will find the problem: getBean(‘foo’) returns dog, but the bar object depends on foo.
But if we look at the logic [create proxy object] as just one implementation among many postprocessors.
- When fetching foo from the cache, a series of postprocessors are called, and then the final result returned by the postprocessors is put into the three-level cache.
- in getBean(‘foo’), also call a series of postprocessors, and then get the object corresponding to foo from the three-level cache, and use it if you get it, otherwise use the postprocessor to return the result.
You will find that, no matter how you toss, getBean(‘foo’) returns the object and the bar object depends on the foo is always the same object.
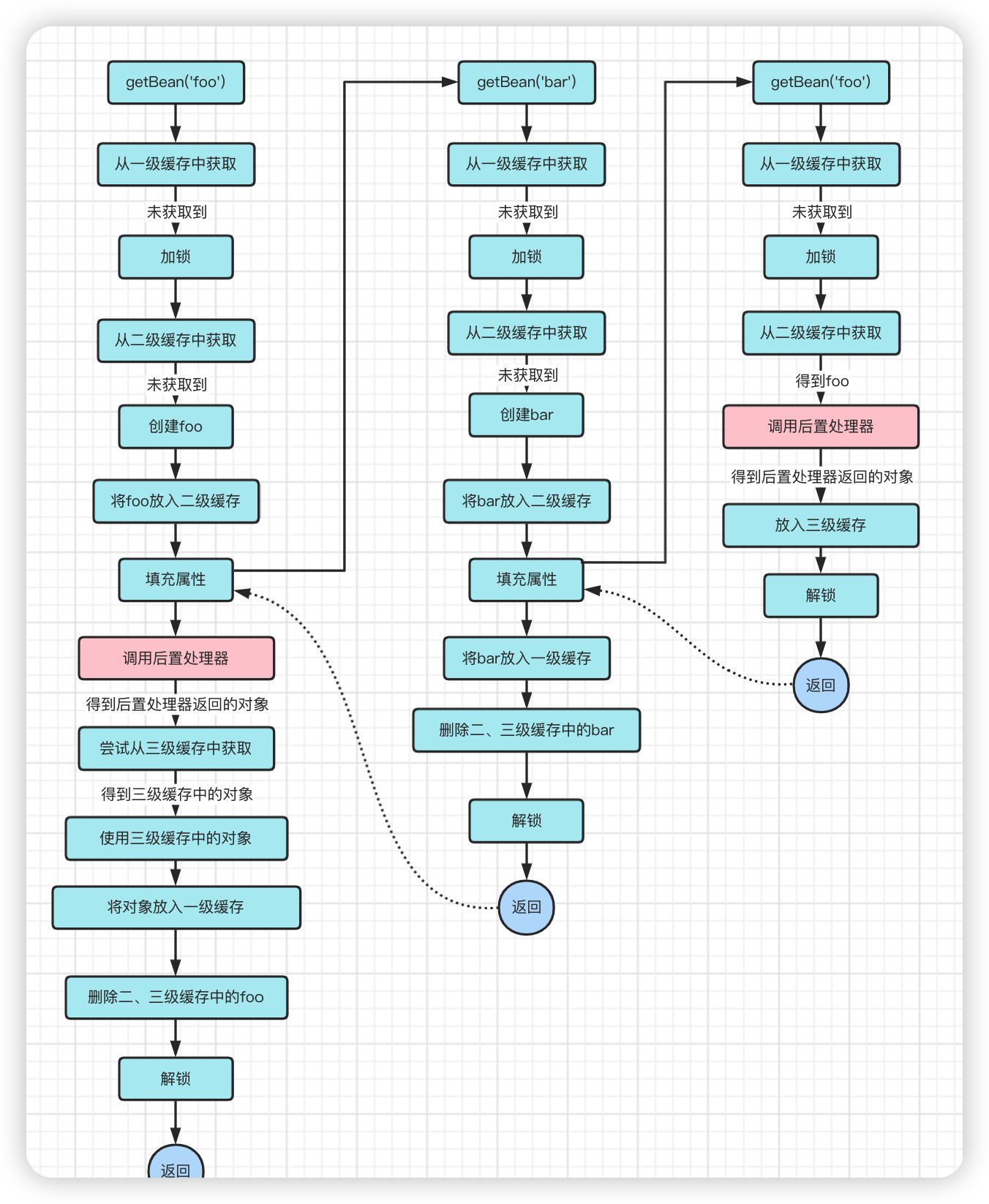
The above is Spring’s solution for cyclic dependencies
My thoughts on this part of Spring’s design
Let’s start with a general review of Spring’s design, which uses a three-level cache
- the first level cache stores the complete bean object
- the second level cache stores anonymous functions
- the third level cache holds the objects returned from the anonymous functions in the second level cache
Yes, Spring has made the two steps we are talking about [fetching foo from the second level cache, calling the post processor] directly into an anonymous function
It has the following structure.
|
|
The content of the function is to call a series of post-processors.
|
|
There has been some controversy about this part of the design: how many levels of caching can be used in Spring to resolve circular dependencies?
Viewpoint 1
The second level of caching can be solved when a cyclic dependency occurs for ordinary objects, but a third level of caching is required when a cyclic dependency occurs for proxy objects.
This is also a common viewpoint
The perspective of this point of view is that when using the second level cache, the occurrence of cyclic dependency will not be a bug, that is, the ordinary object will not, the proxy object will.
In other words: when multiple cyclic dependencies occur, is the object obtained from the cache multiple times, and is the object obtained the same each time?
For example, object A depends on object B, object B depends on object A and object C, and object C depends on object A.
The flow of getBean(‘A’) is as follows.
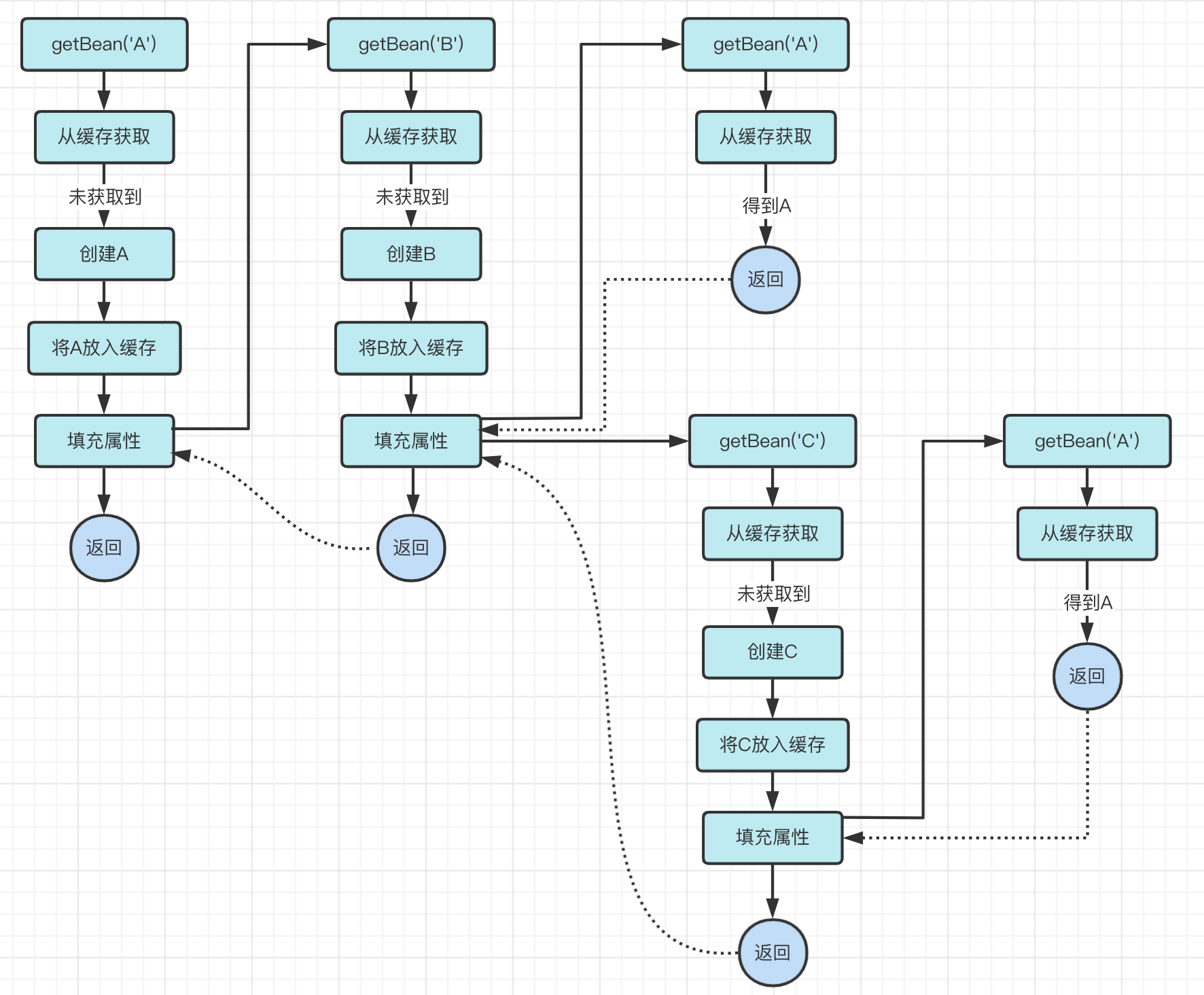
In that process, the A object is fetched from the cache twice.
Now, let’s think about the process in the context of fetching objects from the cache.
Logic when there is only a second-level cache.
- call the anonymous function in the second-level cache to get the object
- Return the object
Assuming that the original object is returned in the anonymous function, there is no proxy creation logic - there is strictly no post-processor logic here
Then the A object returned each time [the anonymous function in the L2 cache is called to get the object] is the same.
So it follows that ordinary objects have no problem when there is only a second-level cache.
Suppose the logic of creating a proxy is triggered in the anonymous function, and the anonymous function returns a proxy object.
Then the proxy object is created each time [the anonymous function in the second level cache is called to get the object].
The proxy object created each time is a new object, so the A object returned each time is not the same.
So it is concluded that the proxy object will have problems when only the second level cache is available.
So why is the tertiary cache OK?
Logic when the three-level cache.
- first try to get from the three levels of cache, did not get
- call the anonymous function in the second level cache to get the object
- put the object into the three-level cache
- delete the anonymous function in the second level cache
- Return the object
So the anonymous function will be called to create the proxy object when it is first fetched from the cache, and each subsequent fetch will be taken directly from the third level cache and returned.
In summary, this argument is valid.
However, I would prefer a more rigorous version of this argument: When the object returned by the anonymous function is the same each time, the second level cache is sufficient; when the object returned by the anonymous function is not the same each time, a third level cache is needed.
Viewpoint 2
This view is also my own: from a design point of view, only a three-level cache can guarantee the scalability and robustness of the framework.
When we review the conclusion of viewpoint one, you will find a very contradictory point: how can Spring know that the objects returned by anonymous functions are consistent?
The logic in anonymous functions is to call a series of postprocessors, which are customizable.
This means that what is returned by the anonymous function is itself outside of Spring’s control.
This is where we borrow the three-level cache to look at the problem and see that:The three-level cache is an effective solution to the circular dependency problem regardless of whether the anonymous function returns the same object or not.
By design, the three-level cache is designed to include the requirements achieved by the two-level cache.
So we can conclude that a design using a three-level cache will have better scalability and robustness than a design with a two-level cache.
If we use view 1 to design the Spring Framework, we have to add a bunch of logical judgments, if we use view 2, then we only need to add one layer of cache.
Summary
The original intent of this post was to write about my thoughts on Spring’s cyclic dependencies, but to be able to speak clearly about this matter, I described Spring’s design for solving cyclic dependencies in detail.