Preface
In the past year, my focus has been on API gateway (AliCloud CSB), which is a new area for me, but inseparable from my previous exposure to microservices governance. API gateways for microservices scenarios require some basic capabilities, one of which is to connect to registries that serve as entry points for microservices. For example, Zuul and SpringCloud Gateway have implemented such a feature. In fact, many open source gateways have major limitations in this feature, so I will not discuss these limitations in this paper, but share my thoughts on it for the common scenario of service discovery.
Concept Clarification
The term service discovery is a bit abstract to be honest, and it makes sense to discuss it in a concrete way in the specific domain of microservices. “The term “service discovery” refers to the process by which a service consumer obtains the service provider’s service address. The term “service” may also be used differently in different microservices frameworks, but most of them refer to applications, interfaces, and other information.
- Spring Cloud represents services in the application dimension
- Dubbo2.x represents services in the interface dimension; Dubbo3.x represents services in the application dimension
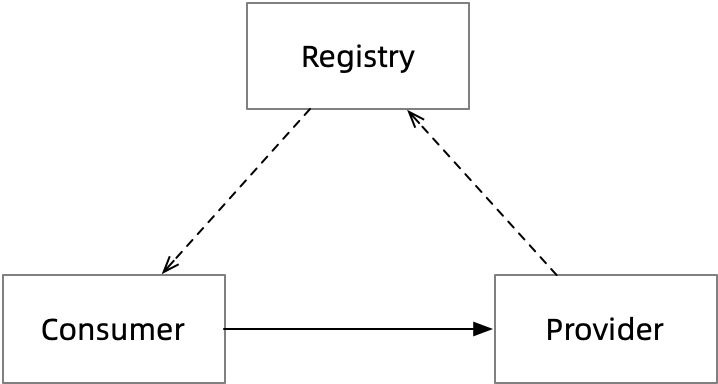
This flow of services from Provider -> Registry -> Consumer is the focus of this paper.
The two ways of data delivery: the push model and the pull model, have been a clichéd topic, and it may be worth talking about in service discovery as well. Let’s not rush to answer the question of who exactly is better in push and pull in this scenario of service discovery, let’s first look at how service discovery is implemented in some microservice frameworks.
Service Discovery in Microservices Frameworks
This section takes a look at two microservices frameworks, Dubbo and SpringCloud, to see whether they use a pull or push model for service discovery.
Dubbo service discovery
|
|
Dubbo’s core interface for managing service discovery, RegistryService, gives a straightforward answer, and the keywords subscribe and notify allow you to guess that Dubbo is using a push model.
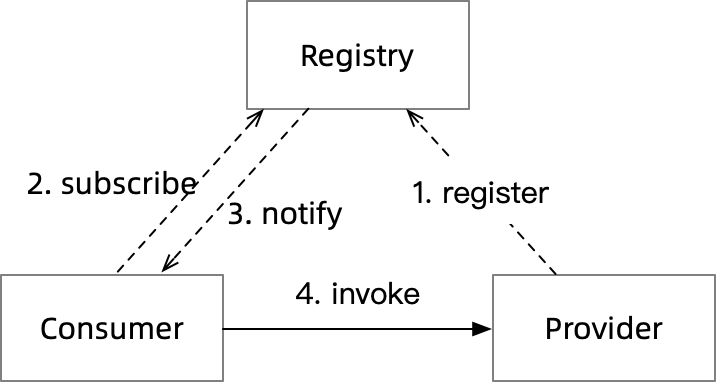
The figure above shows the workflow of a push model.
SpringCloud Service Discovery
|
|
DiscoveryClient is a core interface in SpringCloud for service discovery, and as you can basically see by getInstances, SpringCloud uses a pull model.
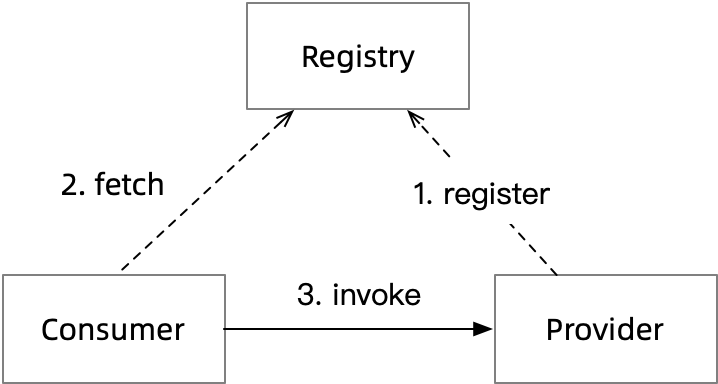
The diagram above shows the workflow of a pull model.
While we haven’t yet navigated the optimization and implementation details behind the two models in detail, it appears from the facts that Dubbo and SpringCloud use different service discovery mechanisms that both allow microservices to play around.
At this point, if you already have the perception in your mind that Dubbo is a push model and SpringCloud is a pull model, you may want to continue reading the next section, and that perception may be shaken up again.
Push and pull in registry
The previous section introduced the push-pull model of service discovery from the perspective of a microservices framework, and this section analyzes it from the perspective of a registry. In the end, whether it is Dubbo or SpringCloud, you have to interface to a registry to get service discovery capabilities, either Zookeeper, Nacos, Eureka, or any other component that provides service discovery capabilities.
I’ll start with Nacos as an example to introduce its push and pull model. Let’s start with the core interface provided by Nacos’ Naming module.
|
|
To facilitate reading, I removed most of the overloaded interfaces and non-core interfaces. As you can see, from the API perspective, Nacos provides both push and pull model interfaces, which makes it easy to be integrated with microservices frameworks. If you are interested, you can read the code of Dubbo/SpringCloud Alibaba integration of Nacos, where Dubbo uses subscribe, a set of push model interfaces, and SpringCloud Alibaba uses selectInstances, a set of pull model interfaces.
Is it enough to say that “Nacos is a registry that incorporates a push-pull model”? Look at getAllInstances, selectInstances, both of which have a subscribe parameter, and follow the source code to explore
|
|
You can see that the subscribe parameter controls whether the service is pulled directly from the registry. When subscribe=false, the service is actually fetched from a local cache maintained by Nacos itself, and in most cases the service is fetched using the subscribe=true overload method. So, selectInstance looks like it’s pulling a service, subscribe looks like it’s pushing a service, and we don’t actually know how the Nacos kernel maintains its cache.
From the above subscribe hint, we can conclude that we cannot directly conclude from individual interfaces whether the registry is using a push model or a pull model, and that the model depends on how the client side loads/updates the service information from the server side.
So, how does Nacos cleint actually get the list of services from the server side in real situations? Without further ado, let’s get to the conclusion.
In Nacos 1.x, Nacos uses a timed pull + udp push mechanism. The client will start a timer to pull the service every 10s to ensure that the service version on the server side is consistent. In order to solve the problem that the client does not receive timely notification when the service is updated within the 10s interval, Nacos also triggers a udp push when the service is updated on the server side.
In Nacos 2.x, Nacos uses a server-side tcp push mechanism. When the client starts up, it establishes a long tcp connection with the server, and when the service changes, it reuses the connection established by the client to push the data.
Therefore, when answering the question of whether Nacos is a push model or a pull model, we need to differentiate between the versions.
Conclusion: Nacos 1.x is a pull model; Nacos 2.x is a push model.
I wonder if any readers are curious as to why Nacos was designed this way, and I’ll briefly use some QA to quickly answer some possible questions.
Q: Why is Nacos 1.x defined as a pull model when Nacos 1.x uses udp push?
A: udp push in Nacos 1.x is mainly designed to reduce the service update latency, and in complex network deployment architecture, such as client and server can only one-way access, or in the case of SLB intermediate media udp will fail. Moreover, udp is inherently unstable, and Nacos will give up pushing after two failed attempts. So it is mainly in pull mode to secure.
Q: Why didn’t Nacos 1.x use the same architecture as Nacos 2.x, i.e., tcp push, in the beginning?
A: Personally, I guess it’s because the pull model is easy to implement, so Nacos 2.x introduced grpc to implement long connections.
Q: Why does Nacos 1.x use short polling for service discovery instead of long polling like the configuration center?
A: In the service discovery scenario, the server side is more concerned about memory consumption. Although long polling does not occupy threads, the server side still holds request/response, causing unnecessary memory waste.
Push and pull models for some common registries.
- Zookeeper: push model
- Nacos 1.x: pull model
- Nacos 2.x: push model
- Eureka: pull model
Well, after introducing the push-pull model of service discovery from the registry perspective, let’s go back to a question: if we use SpringCloud Alibaba + Nacos 2.1 version, which model is it taking for service discovery?
Correct answer: In the microservices framework perspective, sca uses the pull model, a mechanism for synchronizing pull services; in the registry perspective, the application as a client is using the push model in receiving service changes to the push.
Some people may ask, in the end what model is better? Let me compare the two below.
Push-pull comparison
Real-time
Real-time of service push is the main SLA metric of service discovery, which refers to the delay of the client to perceive the change when the service address changes. Imagine that the server is publishing and the IP address has changed, but the client is still calling the old service address after 10 minutes because the address is not pushed in time.
The latency of the pull model-aware service change is the short polling interval + the time taken to pull the service, which in Nacos has an SLA of 10s.
The push model perceives service change latency as the time it takes for the server to push the service, with an SLA of 1s in Nacos.
In terms of real-time, the push model has a greater advantage.
Stress
Both pull and push models put pressure on the server side, but the timing of the two is different.
- The pressure of the pull model is fixed and depends on the polling interval.
- The pressure of the push model depends on the frequency of service changes.
Two scenarios are used for comparison.
- Standing scenario. During daily operation, the list of services generally does not change, and pulling the model leads to unnecessary overhead and puts more pressure on the server side.
- Fast up and fast down scenario. Rapid machine expansion or shrinkage leads to frequent service address changes, and the push volume becomes instantaneous and large, causing greater pressure on the server and client.
A number of optimizations can be made for fast-up and fast-down scenarios, such as push merge, incremental push, data separation, etc. Nacos currently supports push merge as an optimization.
Code complexity
Code complexity is a very important technical selection metric. The simpler the code, the easier it is to maintain and the more durable it is. Architects need to find a balance between code complexity and performance trade offs, and admittedly, the push model is often much more complex than the pull model, for example, with the extra link of state management for long connections.
The pull model wins out completely.
Summary
This article does not want you to get caught in the wording to determine whether a framework or tool is a push or pull model, but rather to introduce the workflow of the push and pull model in service discovery, so that you can have a deeper understanding of these microservice frameworks or registries.
To summarize, both push and pull models are used in the service discovery mechanism of the mainstream microservice frameworks and registries, and how to choose and optimize them can be based on the characteristics of their own services and the scale of their services.
In my API gateway (AliCloud CSB), I adopt an independent service discovery mechanism that supports both pull model and push model to adapt to some registries that only support push model or only support pull model.
Reference:
https://mp.weixin.qq.com/s/vCwfI5spW57X-tG8C7a87Q